Green Builds Are a Weak Signal
In many organizations, CI status becomes the proxy for release safety: a green pipeline signals readiness, while a red pipeline signals risk.
This binary framing works at small scale but breaks as systems grow.
A passing build does not answer critical questions about which business-critical flows were validated, how stable the underlying signals are, what changed compared to the previous release, or where risk actually concentrates.
As test volume increases, signal clarity often declines.
Reliable feedback is not a byproduct of more tests; it is a product of system design.
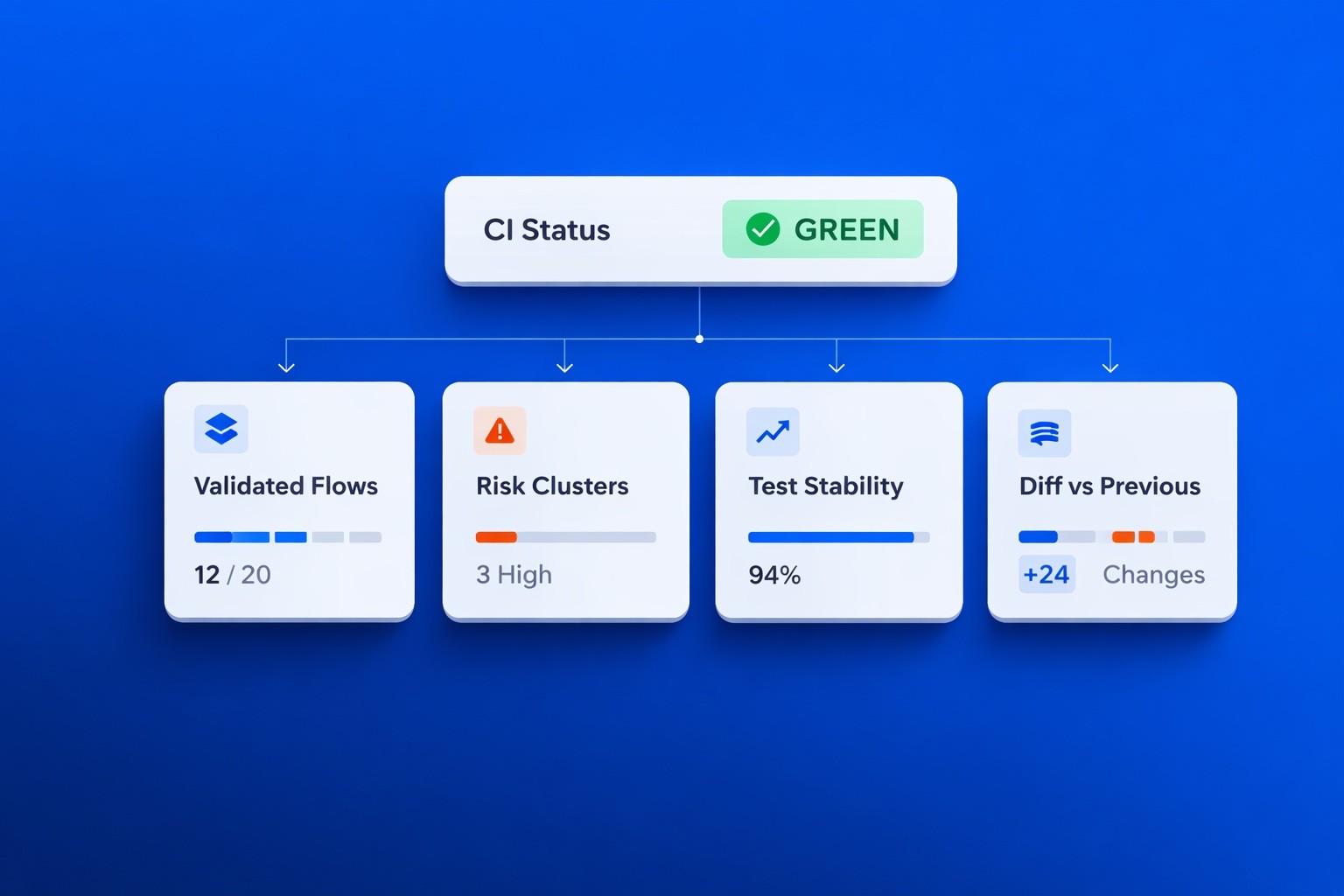
The Hidden Drift in Growing Test Suites
As delivery systems mature, test suites rarely shrink. They accumulate as new features introduce additional checks, bug fixes add regression coverage, and integrations expand validation layers. Over time, the system becomes heavier, but not necessarily clearer.
This is where drift begins.
Drift does not mean fewer tests; it means weaker alignment between what is tested and what truly matters.
Teams experience this drift in subtle ways: CI runs grow longer while providing less clarity, failures require investigation to determine whether they are real, and release decisions increasingly rely on manual judgment despite extensive automation.
At scale, this creates a paradox: more automation, less confidence.

Signal Instability: The Cost of Flakiness
Flaky tests are not merely technical annoyances; they reshape organizational behavior.
When failures occur intermittently, teams begin to treat them as optional signals. Engineers rerun builds, temporary ignores become permanent, and quarantine lists expand.
Over time, a red build no longer demands immediate attention, a green build no longer guarantees stability, and CI turns into background noise rather than a decision tool.
This behavioral shift is costly.
For leadership, the issue is not flakiness itself but the erosion of signal authority. Once engineers stop trusting automation, they compensate with intuition and manual checks. Delivery slows, even when pipelines remain fully automated.
Reliable feedback depends on deterministic signals. Without stability, automation becomes theater.

Coverage Without Context
Coverage metrics are often presented as evidence of maturity. High percentages suggest discipline and thoroughness, yet coverage alone does not indicate relevance.
A product may have extensive unit-level validation while critical integration paths remain under-tested. A marketing funnel may be fully covered at the UI level while edge-case payment flows receive minimal scrutiny.
Without risk alignment, coverage numbers create a narrative of completeness that does not reflect operational reality.
For leadership, the more relevant question is whether revenue-critical flows are consistently validated, whether recent changes receive proportionate scrutiny, and whether high-impact areas are monitored more rigorously than peripheral ones.
Coverage is a volume metric. Risk alignment is a signal metric.
Designing Feedback as a System
Reliable test feedback does not emerge organically; it must be engineered.
Leading organizations treat CI not as a gate but as a signal network composed of stable checks, prioritized execution layers, observable health indicators, and clear ownership boundaries.
Rather than asking whether everything passed, teams distinguish between release-critical signals, advisory signals, and failures that indicate systemic instability.
This layered approach reduces ambiguity and improves decision velocity.

Risk-Based Execution in Practice
Full regression on every change is rarely efficient at scale.
Risk-based execution prioritizes validation based on code change impact, historical defect density, business exposure, and customer visibility. Critical flows are validated immediately and consistently, while lower-risk components may be evaluated asynchronously or in broader cycles.
This approach does not reduce quality; it increases precision.
For CTOs, the result is improved cycle time without sacrificing visibility into material risk.
Making Feedback Measurable
Reliable systems expose their own health.
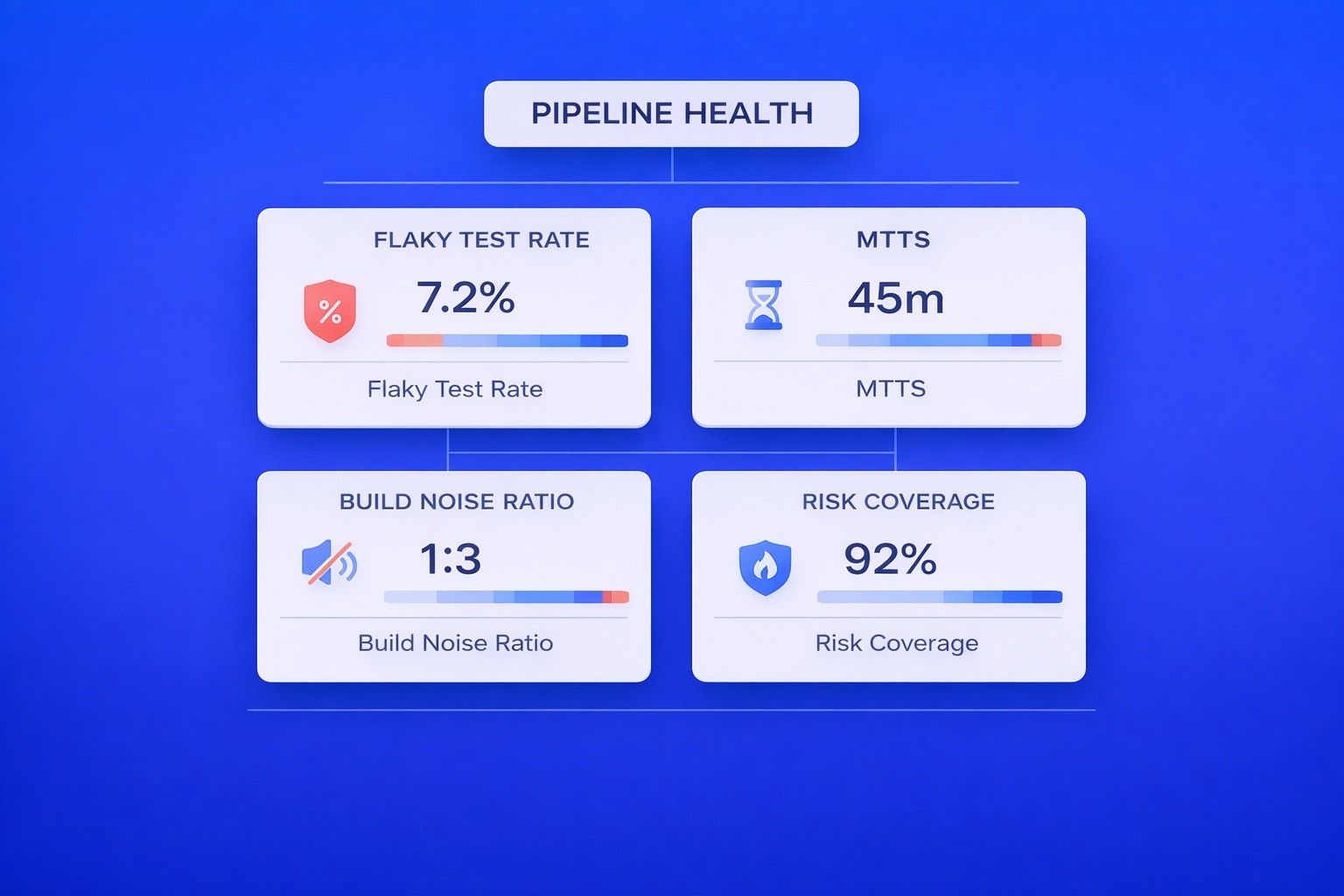
Leadership should track indicators such as flaky test rate, mean time to stabilize failing tests, build failure noise ratio, correlation between green builds and production incidents, and risk coverage for high-impact journeys. These measures transform feedback reliability from an assumption into a measurable operational parameter.
When signal quality becomes visible, it can be governed.
Leadership Implications
For CTOs and engineering leaders, the challenge is not automation scale but decision reliability.
A green pipeline should reduce uncertainty, while a failing pipeline should isolate meaningful risk. If neither condition consistently holds, the system requires redesign.
Reliable test feedback enables faster release approvals, reduces manual verification, clarifies post-incident analysis, and improves delivery predictability. It shifts the conversation from “How many tests do we have?” to “How trustworthy are our signals?”
Conclusion
Reliable test feedback is not about expanding automation but about protecting the integrity of the signals that guide release decisions.
As systems grow, green builds alone are no longer sufficient. Stability, risk alignment, and measurable signal quality determine whether CI informs decisions or merely accompanies them.
Organizations that engineer feedback intentionally move from test volume to signal reliability and from assumed confidence to operational predictability.
Feb 18, 2026

Drives the technical vision at Ramotion, uniting engineering excellence with design innovation to deliver scalable, secure, and user-focused digital solutions.