
Data is at the heart of every decision, transaction, and innovation. Whether running a startup or scaling an enterprise, hiring a web app development agency that understands the value of data processing can help turn raw information into intelligent, actionable solutions.
This article will explore data processing, why it matters, and how it powers everything from e-commerce systems to AI.
Read along and discover the key steps, tools, and real-world examples that make data processing a critical part of today’s technological sphere.
Introduction to Data Processing
Data processing is the foundation of today’s digital systems. It refers to the method of turning raw data into meaningful information using a set of steps or tools. From smartphone apps and a business dashboard to even your smart home devices, everything depends on it.
Data processing plays a significant role in data analytics, helping organizations make more intelligent decisions based on facts and data insights. It also drives automation, from chatbots to factory machines, and supports healthcare, finance, and education progress. Thus, modern technology performs as we know it with the power of data processing.
Defining Data Processing
Data processing turns raw data into usable information that people or systems can understand and act on. This process uses tools, algorithms, and systems to handle everything from collecting the input data to delivering precise, beneficial results as processed data.
In today’s digital world, large volumes of data are generated every second from businesses, apps, and machines. It is crucial to turn these meaningless numbers into high-quality information. Data processing organizes and refines that information to be used to make decisions, spot trends, or even train machine learning models.
Definition and digital ecosystem role
Hence, data processing plays a vital role in the digital ecosystem. It supports everything from daily business operations to advanced analytics and automation. It can help retailers manage customer data or allow a healthcare system to predict patient needs.
The foundation of these processes is a strong data and process foundation. It ensures that the information being used for data processing is accurate, timely, and valuable, deriving useful trends and insightful outputs for decision-making and analysis.
Why Is Data Processing Essential?
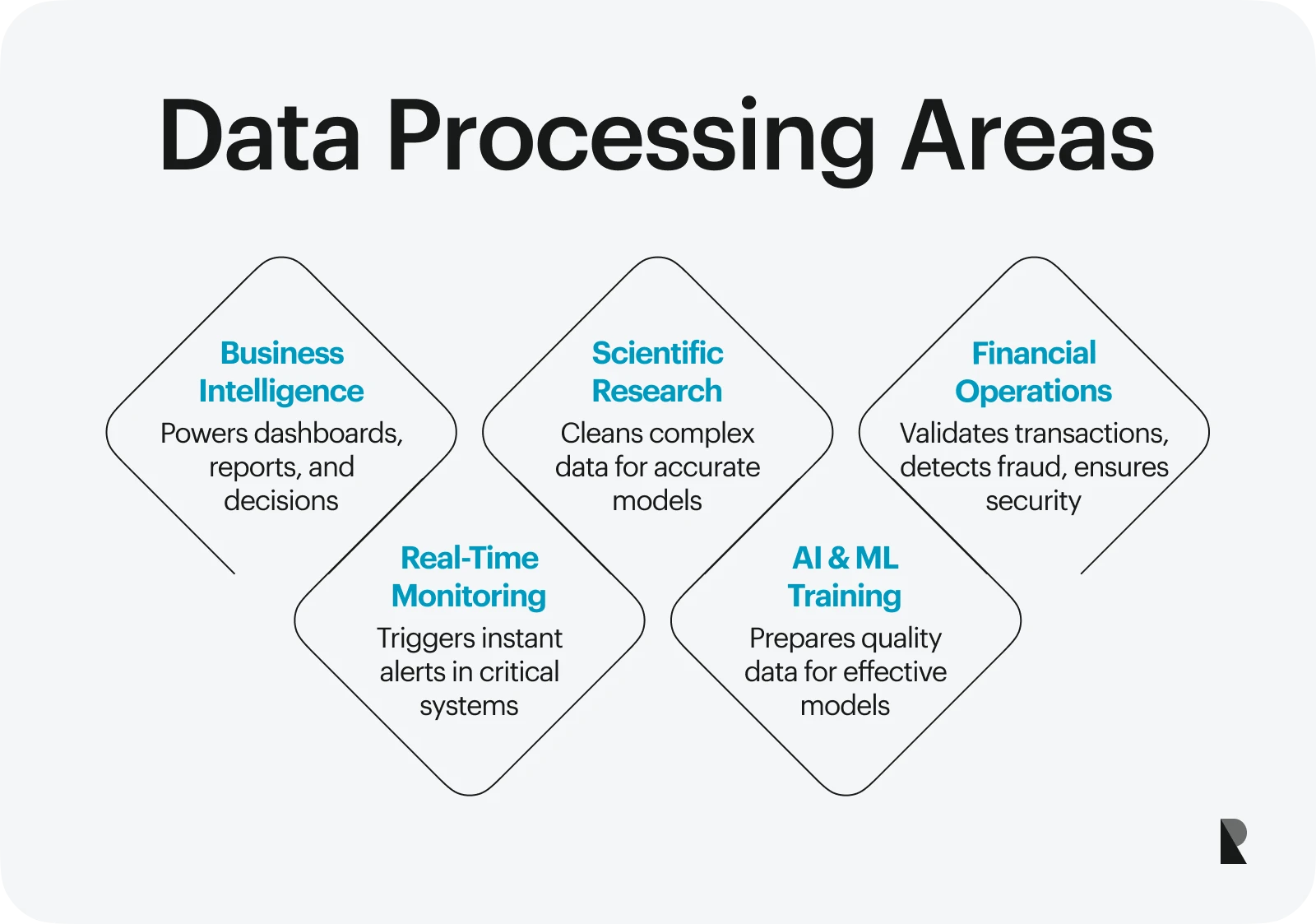
Data processing makes the world's information useful. Raw data from different sources, like sensors, apps, or databases, is messy and hard to understand. Data processing takes that raw input, cleans it, organizes it, and turns it into clear insights. This helps people and systems make better choices, respond faster, and plan smarter.
Without data processing, even the most advanced tools or platforms would struggle to use the vast amounts of real-time data. Whether it is a business, a hospital, or a research lab, processing data helps unlock the full value of the information they collect. Let’s dig deeper into its importance.
Business intelligence & decision-making
In the business world, processed data powers tools like dashboards and reports. These help teams spot patterns, track performance, and make data-driven decisions. For example, a sales team can look at processed weekly data to adjust their strategy, while leadership uses visual reports to plan for the future. Data scientists often support these efforts by using structured data from multiple databases.
Scientific research & modeling
Researchers use data processing to handle large and complex data sources. Raw data must be cleaned and processed in fields like genomics, climate science, or physics before models can be built or discoveries made. For instance, scientists studying DNA sequences rely on processed information to find patterns and understand genetic traits.
Financial operations & validation
Banks and fintech companies rely heavily on data processing to manage millions of transactions daily. Data processing helps them validate transfers, detect fraud, and settle payments almost instantly. By processing real-time and historical data, they can ensure that operations stay accurate and secure.
Real-time monitoring & alerts
In industries like transportation, energy, and public safety, real-time data must be processed quickly to trigger alerts or actions. Key examples include traffic systems that use data from cameras and sensors to adjust signals on the fly and smart factories that process equipment data to prevent breakdowns before they happen.
Machine learning & AI training
Training machine learning and AI models requires large volumes of structured, high-quality data. Before this data can be used, it must go through thorough processing: removing errors, organizing inputs, and selecting the right features. This is crucial in ensuring models learn accurately and perform well in real-world tasks.
Thus, data processing is essential because it turns raw input into valuable insights that drive real impact. It is what makes information truly useful, from everyday decisions to advanced scientific breakthroughs.
Main Stages of Data Processing
Turning raw data into valuable insights is not a quick and straightforward process. The information must undergo several key steps, each playing an important role. These stages of data processing ensure that the data we use is accurate, clean, and ready for action.

Main data processing stages
Let's walk through each processing stage, breaking down their role.
1. Collecting raw data
The first step is data collection. This is where data is collected from various sources, including APIs, system logs, sensors, CRM platforms, websites, or mobile apps. At this stage, the data is usually unorganized and not yet ready to use, but it lays the foundation for the complete process.
2. Data preparation: cleaning & transformation
Once the data is collected, the next step is data preparation. This includes data cleaning, where you fix errors, remove duplicates, and convert data into a usable format. For example, dates may need to be standardized or missing values filled in. Clean data ensures that the results derived later are reliable and accurate.
3. Data input
In this stage, the cleaned and prepared data is moved into the system for processing, known as data input. The data might be entered into data warehouses, analytics platforms, or other processing engines. It is like getting everything in the right place before the real analysis begins.
4. Algorithmic processing
This is the core of data processing where the system applies rules, algorithms, or logic to the input data. Processing involves sorting, aggregating, calculating values, and enriching the data more contextually. This step turns the raw content into structured and meaningful results.
5. Output & interpretation
After processing, we get the data output. This can be visual dashboards, reports, summaries, or automated alerts and actions. The goal is to make the data easy for people or machines to understand and use. This stage focuses on getting valuable insights from the data input and making decisions accordingly.
6. Data storage
Finally, the processed data is stored for future use. Data storage is essential for keeping records for compliance, enabling further analysis, or maintaining a historical view over time. The data may be stored in cloud storage, databases, or secure archives, depending on the system.
In this complete system, each processing stage works together to ensure data moves from raw and unstructured to clear and useful. These steps are key to getting reliable and high-quality results from raw collected information.
Types of Data Processing
There is no one-size-fits-all method for working with data. Different situations require different approaches, depending on the processing tasks' speed, scale, and complexity.
Below are the main types of data processing used across industries today.

Key types of data processing
Batch processing
Batch processing is a method where large volumes of data are collected, stored, and processed at a scheduled time. This is ideal when results do not need to be instant, such as generating nightly sales reports or updating customer records at the end of the day. It is commonly used in electronic data processing systems where efficiency and automation are key.
Real-Time processing
Real-time processing handles data immediately as it arrives. This method is essential for applications that depend on quick reactions, such as fraud detection, live stock trading, or medical sensors monitoring patient vitals. The processing system must be fast, reliable, and able to manage constant data flow.
Online processing
Online processing is also known as transaction or interactive processing. It works when users take specific actions. For example, when someone makes an online purchase or searches a website, the system processes that request instantly. This method is widely used in customer-facing apps, e-commerce platforms, and banking systems.
Distributed processing
Distributed processing spreads tasks across multiple machines or servers, enabling it to handle massive datasets and perform complex operations. This setup improves speed, system performance, and resilience. Modern tools often use data lakes and cloud services to support distributed processing across regions and time zones.
Manual processing
Manual processing is still used in environments without access to advanced tools. It involves humans performing tasks like data entry or basic calculations. This method is more common in low-tech regions or small-scale operations where automation has not been adopted.
Each of these processing methods serves a unique purpose. Choosing the right processing system can make your data more manageable, actionable, and impactful.
Different data processing approaches are used based on where, how, and by whom the data is being processed. Choosing the right approach can affect everything from performance to security, cost, and even how quickly you can act on your data.
The primary data processing approaches used across industries and their comparison are discussed below.
Centralized vs. decentralized
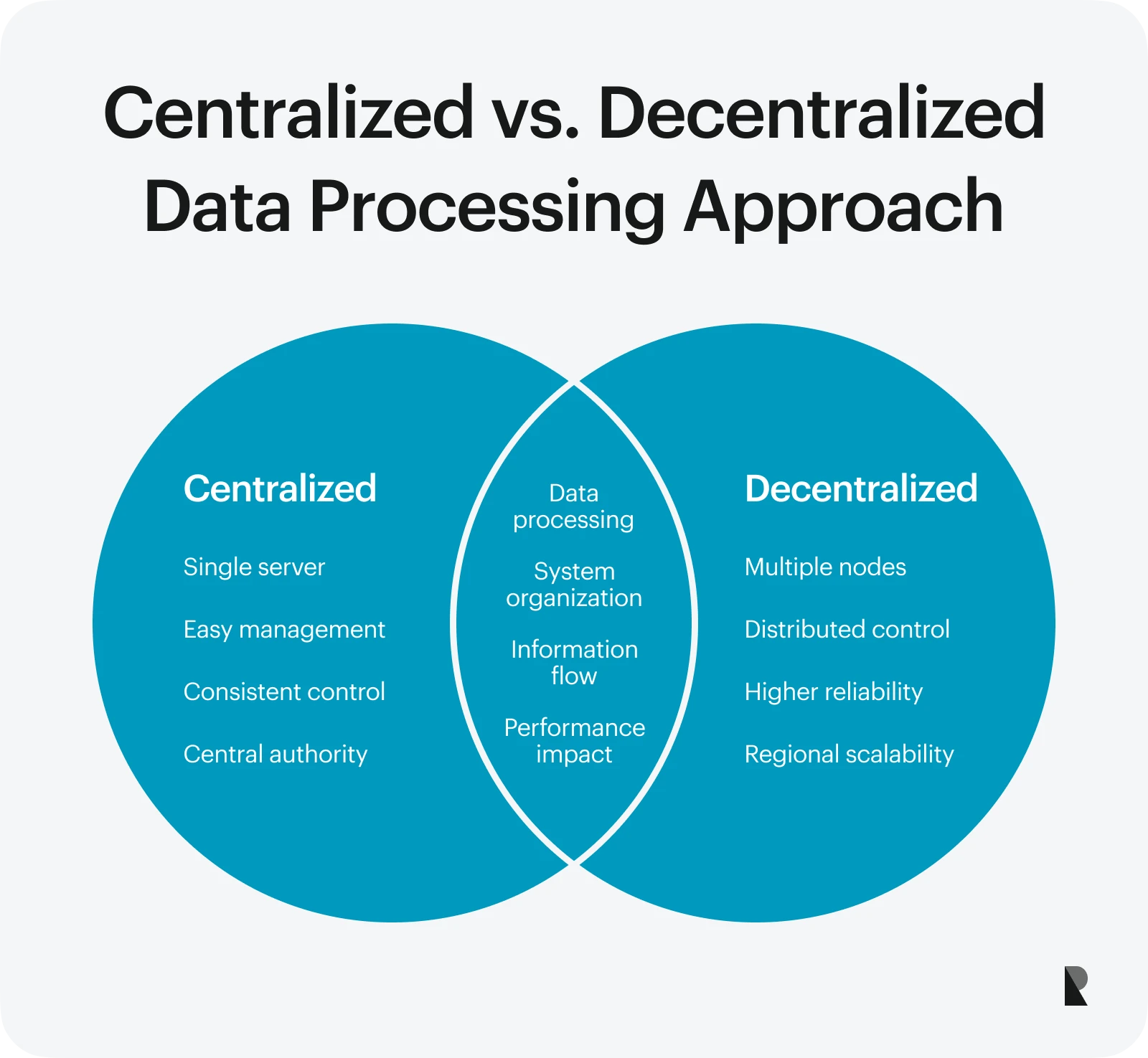
In a centralized system, all data processing methods occur in a single location or server, making it easier to manage and ensure consistent results. However, this approach is difficult to manage when focusing on real-time processing or dealing with high traffic.
Meanwhile, a decentralized system spreads processing across multiple locations or devices. This can improve speed, reliability, and performance, especially when handling large datasets from different regions. It is a typical setup in distributed organizations or global platforms.
Automated vs. manual
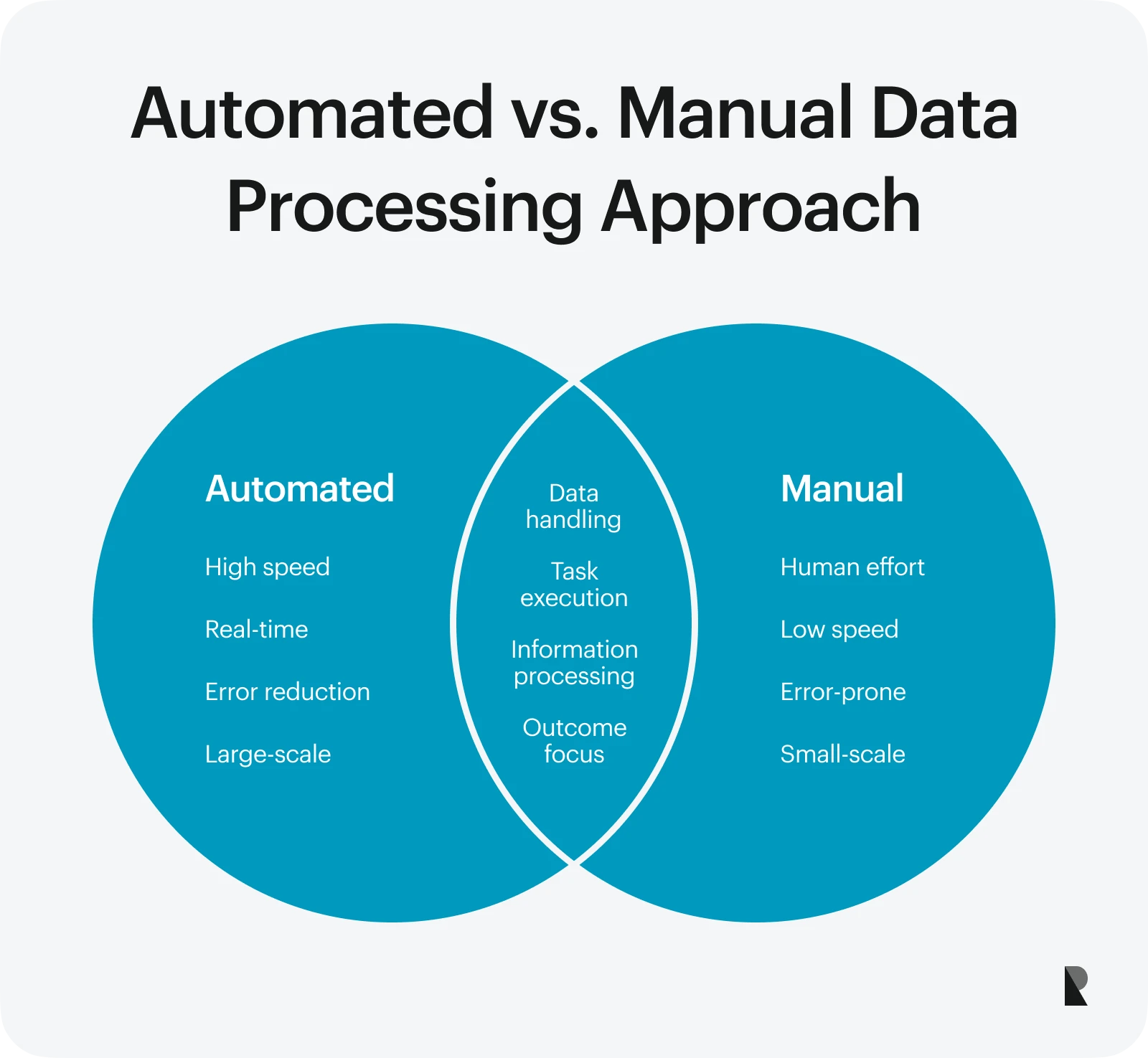
Automated data processing uses systems and tools to handle data without human input. It is faster, more accurate, and ideal for handling high volumes of data. It also supports real-time processing, which is perfect for dynamic applications like fraud detection or live analytics.
Manual processing, on the other hand, involves human effort for tasks like data entry or basic calculations. While this method is still used in smaller or low-tech setups, it is slower and more prone to errors. Automation helps ensure quality data by reducing mistakes and saving time.
Cloud-Based vs. on-premise
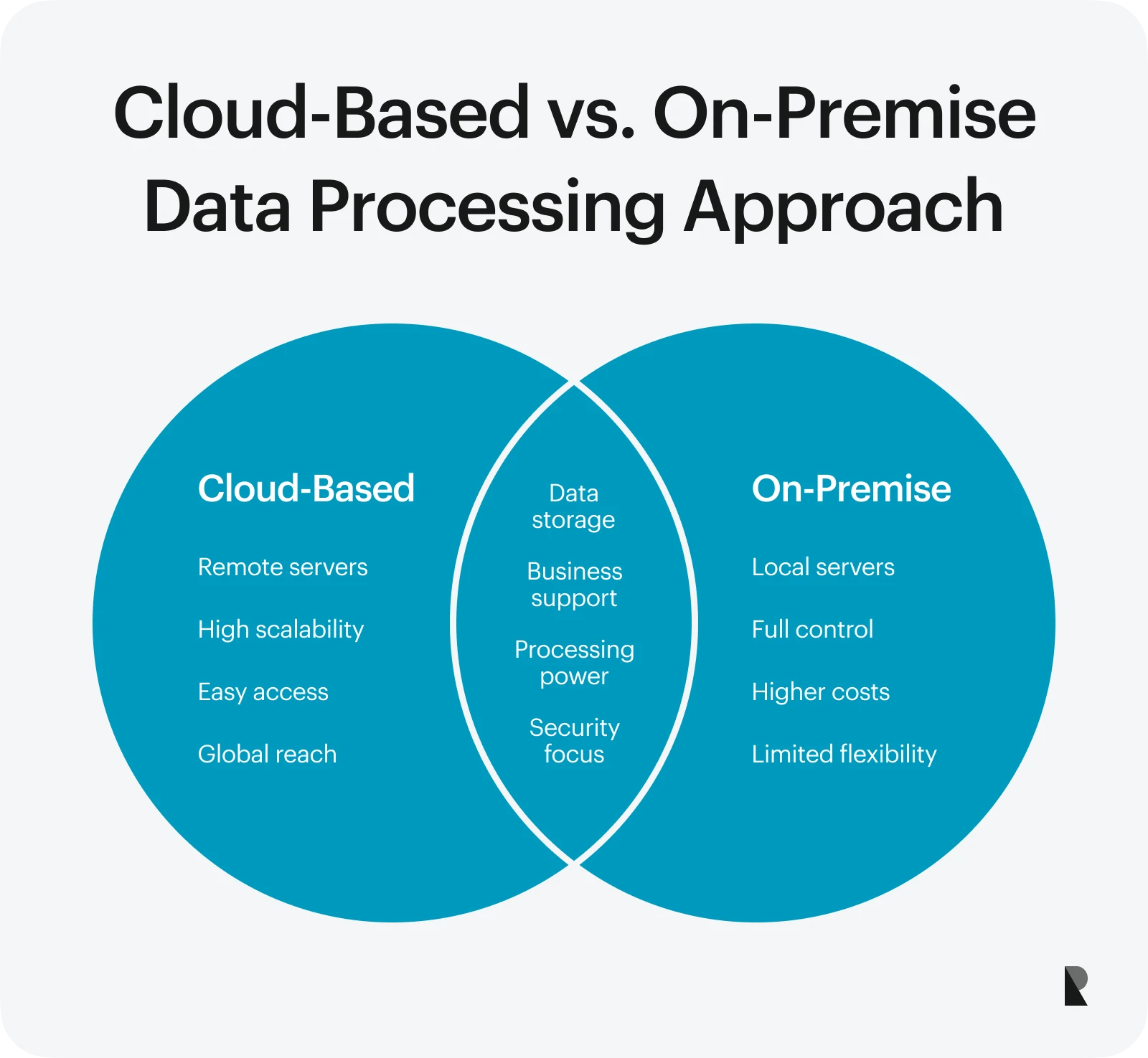
A cloud-based approach processes data on remote servers provided by cloud services. It offers excellent flexibility, high scalability, and easy access from anywhere. This approach is ideal for companies needing to process large data sets or run global operations.
Meanwhile, an on-premise approach keeps everything in-house. The organization owns and manages the servers. While this provides more control and added security, it can be costly to maintain and may lack the flexibility of cloud systems.
Choosing the right approach depends on your goals, infrastructure, and the kind of data you are working with. Understanding these options enables you to build smarter, more efficient data processing systems.
Common Data Processing Tools
With so many data processing tools available today, choosing the right one can be tricky. Some tools are built for speed, others for handling big data, and some focus on real-time processing.
Whether you are a data analyst, developer, or part of a business intelligence team, knowing what each tool offers is essential. Here is a list of widely used data processing tools.

Choosing the right data processing tool is based on your needs
Apache Spark
It is one of the most powerful large-scale data processing and analytics tools. While it is built in Scala, it also supports Python, Java, and R through APIs.
Spark is designed for speed and scalability, making it ideal for handling big data across distributed computing clusters. It integrates well with Hadoop, Kafka, AWS, and Azure. It is often used when fast performance is required for tasks like machine learning, graph processing, or real-time analytics.
Apache Kafka
It is a leading tool for real-time processing of streaming data. Written in Java and Scala, it is designed to manage high-throughput data pipelines easily.
Kafka is highly scalable and fault-tolerant, making it perfect for use cases like fraud detection, log monitoring, and system tracking. It integrates with tools like Spark, Flink, PostgreSQL, and cloud platforms. It is widely used where immediate data response is critical.
Microsoft Power BI
It is a popular business intelligence tool that helps users visualize and analyze data through interactive dashboards and reports. It uses DAX and Power Query (M) as its main languages and is scalable enough for both small teams and large enterprises.
Power BI integrates smoothly with Excel, SQL Server, Azure, and Google Analytics. It is an excellent choice for turning processed data into meaningful insights for decision-making.
Apache Hadoop
It is a trusted tool for storing and processing massive amounts of electronic data. It is built in Java and works well in distributed environments, allowing it to scale easily across multiple machines.
Hadoop supports batch processing and is best suited for jobs that do not require real-time responses. It integrates with tools like Hive, Pig, HBase, and Spark, and is ideal for organizations that deal with big data regularly.
Google BigQuery
It is a cloud-based data warehouse that allows fast querying of large datasets using SQL. It is built for automated scaling, handling everything from small databases to petabytes of information without server management.
BigQuery integrates seamlessly with Google Cloud tools and visualization platforms like Looker and Tableau. It is a go-to solution for teams working on cloud-native analytics at scale.
Talend
It is a data integration platform built in Java that helps teams move, clean, and transform data across systems. It is well-suited for big data and business intelligence projects.
Talend offers strong scalability for growing data needs and integrates with various tools, including Salesforce, AWS, Azure, and Snowflake. It is beneficial for building reliable data pipelines and preparing data for reporting or analysis.
| Tool | Purpose | Language | Scalability | Integrations | Best For |
|---|---|---|---|---|---|
| Apache Spark | Large-scale data processing and analytics | Scala (APIs for Python, Java, R) | Extremely scalable across clusters | Hadoop, Kafka, AWS, Azure | Processing big data and running complex analytics fast |
| Apache Kafka | Real-time data streaming and processing | Java and Scala | Highly scalable across distributed systems | Spark, Flink, PostgreSQL, cloud services | Real time processing like fraud detection and log monitoring |
| Microsoft Power BI | Data visualization and business intelligence | DAX, Power Query (M) | Suitable for small to enterprise businesses | Excel, SQL Server, Azure, Google Analytics | Creating interactive dashboards and reports |
| Apache Hadoop | Storing and processing massive big data sets | Java | Designed for large-scale environments | Hive, Pig, HBase, Spark | Batch processing of electronic data across systems |
| Google BigQuery | Cloud-based data warehouse and analytics | SQL | Automatically scales to petabytes | Google Cloud services, Looker, Tableau | Fast queries over very large datasets in the cloud |
| Talend | Data integration and transformation | Java | Good for medium to large data projects | Salesforce, AWS, Azure, Snowflake | Moving and preparing data for business intelligence use |
Thus, choosing the right tool will ensure you get fast, accurate, and scalable results. You must carefully analyze each of these tools before opting for one, as each serves a unique role in the world of data processing.
Open Source vs. Commercial Tools
When it comes to choosing tools to process data, one of the key decisions is whether to use open-source or commercial software. Both have strengths and challenges, depending on your budget, team size, and technical skills.
Let's break down the differences to help you decide what suits your needs best.
Licensing & cost
Open source tools are generally free, making them a cost-effective option, especially for startups, small teams, or research projects. Since there are no licensing fees, you can test, scale, and explore different ways to process data without worrying about high costs.
Meanwhile, commercial tools come with licensing fees. The cost depends on the features, number of users, and scale of your operations. While more expensive, these tools provide extra functionality, professional support, and regular updates, making them a better fit for larger organizations.
Features & scalability
Commercial tools usually offer a wider range of built-in features, user-friendly interfaces, and ready-to-use integrations. They are often designed to scale smoothly with growing data needs, allowing teams to efficiently handle large volumes of data.
Open source tools are highly flexible and customizable. You can modify them to fit your needs, which requires more technical expertise. While they may not come with all the advanced features, they provide strong performance, mainly when used with the correct configurations and support tools.
Support & community
Support for open-source tools mainly comes from a large community of developers and users. Online forums, GitHub, and documentation can help troubleshoot issues or improve your setup. This is helpful but time-consuming if you are under tight deadlines.
Commercial tools offer official, dedicated support with customer service, help desks, and training programs. This level of support is particularly valuable for companies that need to ensure smooth, uninterrupted operations while working with sensitive or large-scale data.
Hence, your goals will define your choice of data processing tool. While open-source tools offer flexibility and low cost, advanced features with professional support are only available with commercial tools. You must weigh your options and budget before choosing either one.
Real-World Data Processing Examples
Data processing is crucial to many of our daily activities. From online shopping to weather updates, real-time systems and intelligent tools rely on the ability to process data quickly and accurately.
Below are a few real-world examples that show how data processing makes a difference: E-commerce Transactions
Online stores use real-time systems to process orders, payments, and inventory data. This helps confirm purchases instantly, update stock levels, and prevent errors during checkout.
Weather forecasting
Satellite images and sensor data are constantly collected and processed to analyze weather patterns. This enables accurate and timely forecasts that help people and businesses prepare for changing conditions.
Fraud detection in finance
Banks and fintech platforms monitor millions of transactions daily. They process data in real time to detect unusual activity, flag suspicious behavior, and prevent fraud before it causes harm.
These examples highlight how critical it is to process data quickly and accurately, whether for safety, convenience, or more intelligent decision-making.
Conclusion: The Value of Data Processing
As the world becomes more data-driven, efficient data processing is a strategic necessity. Large volumes of data are created across industries every second, but raw data alone holds little value unless it is processed into something meaningful.
With the rise of AI and machine learning, the need for clean, structured, and timely data is even greater. AI models rely on high-quality, well-processed data to deliver accurate results. Thus, data processing ensures organizations stay competitive in an ever-evolving digital sphere.
Aug 21, 2025

Creates insightful, strategy-driven content that translates complex design and branding concepts into accessible knowledge, supporting Ramotion’s mission to elevate digital experiences.